I have been working a lot on Spark and Scala. I have really like scala as a language, due to its numerous advantages over Java, the foremost being that for a simpler API having Type classes and Default Method Arguments does wonders. Also, idiomatic scala code uses higher order functions, so it encourages a functional style of programming.
I also like spark a lot, but couldn't stand the innefficient way it was being used, i.e. processing a bunch of sql queries sequentially. I strongly believe, Spark wasn't designed to be used this way.
A SparkSession supports executing multiple queries in parallel provided ofcourse that they are independent. So, there was a clear optimization opportunity in Orchestrating i.e. wresting control of execution, whilst providing sufficient callback mechanisms. Thus, I developed a framework which given a set of queries and their dependencies builds a DAG [1]. It then uses dynamic programming to find out the depth of each node correctly. The idea, then is to to create stages corresponding to the nodes at each depth and as they are independent, they can be executed in parallel.
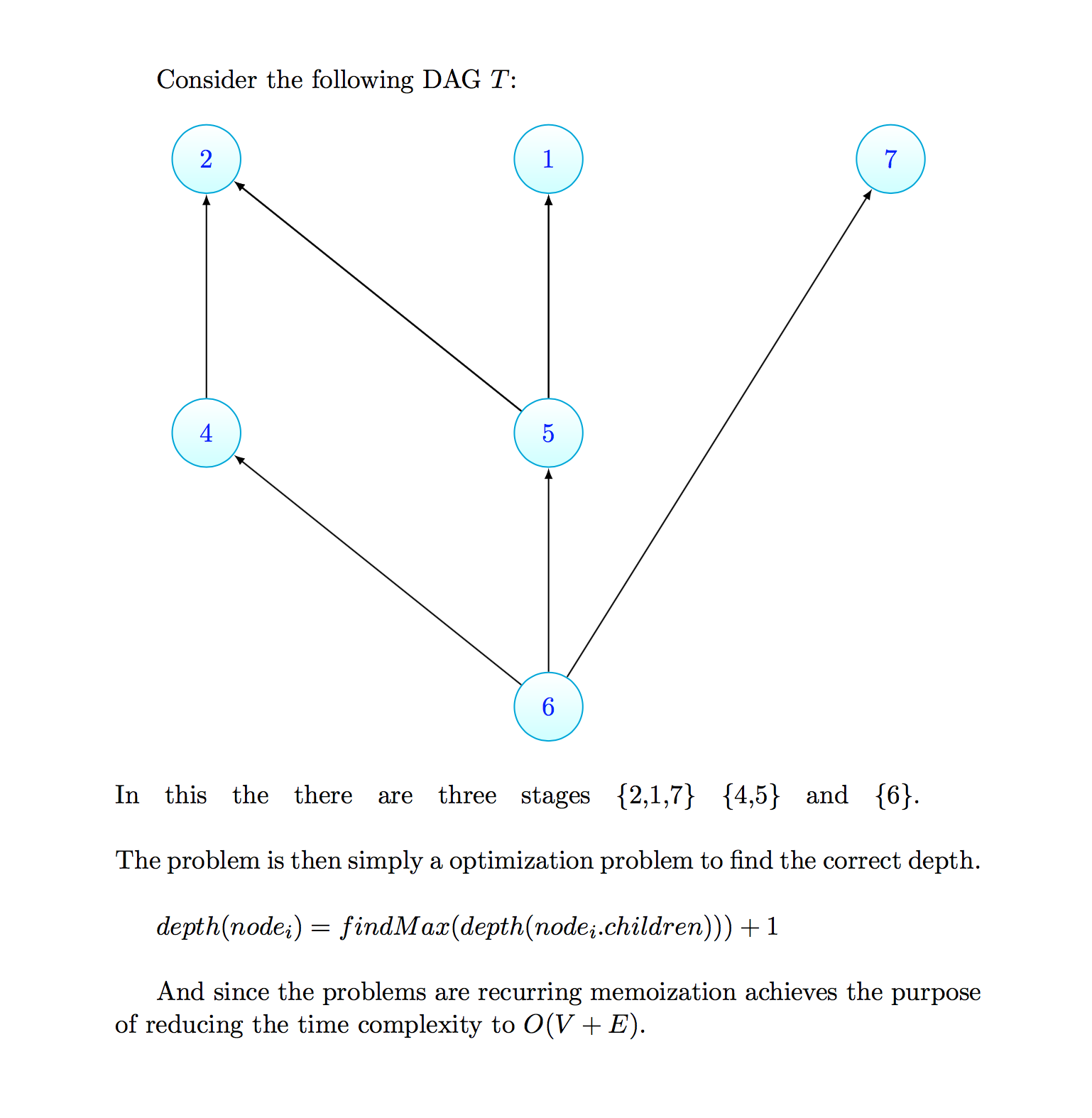
Once we have the DAG's stages, the execution is pretty straightforward using ExecutorService and configuring an implicit instance of the ExecutionContext to use the configured ExecutorService.
In general, for a framework, once you wrest control of execution there are numerous advantages, some of the potent ones are reusability, optimization and maintaenability.
The framework thus developed has the following features:
- Optimization : Parallel execution of query or custom processing steps.
- Global and Local bind variable substitutions.
- Ability to enable explain plan by turning on configuration option.
- JSON based logging using a AsyncAppender [2] (this is essentially a BlockingQueue, as multiple threads can write and only a single consumer should write to the log file.), so can be easily integrated with splunk.
- Custom UDF registration and default registration of a bunch of common UDF's.
- Custom hooks into the execution by implementing a trait which is then invoked at the right stage by the Orchestrator (Inversion of Control).
- Configuration based coding (users don't need to know scala or spark to use it). And,
- Reusability and Maintaenability.
| [1] | DAG: https://en.wikipedia.org/wiki/Directed_acyclic_graph |
| [2] | AsyncAppender: https://logback.qos.ch/manual/appenders.html#AsyncAppender |
comments powered by Disqus